Motivation
深度学习算法和GPU算力的不断进步正促进着人工智能技术在包括计算机视觉、语音识别、自然语言处理等领域得到广泛应用。与此同时,深度学习已经开始应用于以自动驾驶为代表的安全攸关领域。但是,近两年接连发生了几起严重的交通事故表明深度学习技术的成熟度还远未达到安全攸关应用的要求,因此对可信人工智能系统的研究已经成为了一个热点方向。
背景知识
这一部分作者简单介绍了深度学习的发展史、基本概念,深层神经网络DNN,DNN 运行框架,以及运行DNN 实时任务的嵌入式硬件平台包括嵌入式 GPU 和网络加速器。
深度学习发展史
神经网络早在1943年就被提出,但1969年 Marvin Minsky 教授在书中证明感知器模型只能解决线性可分问题,无法解决异或问题,并且给出“基于感知器的研究注定将失败”的结论。这导致了神经网络陷入低潮,停止发展了将近10年之久。
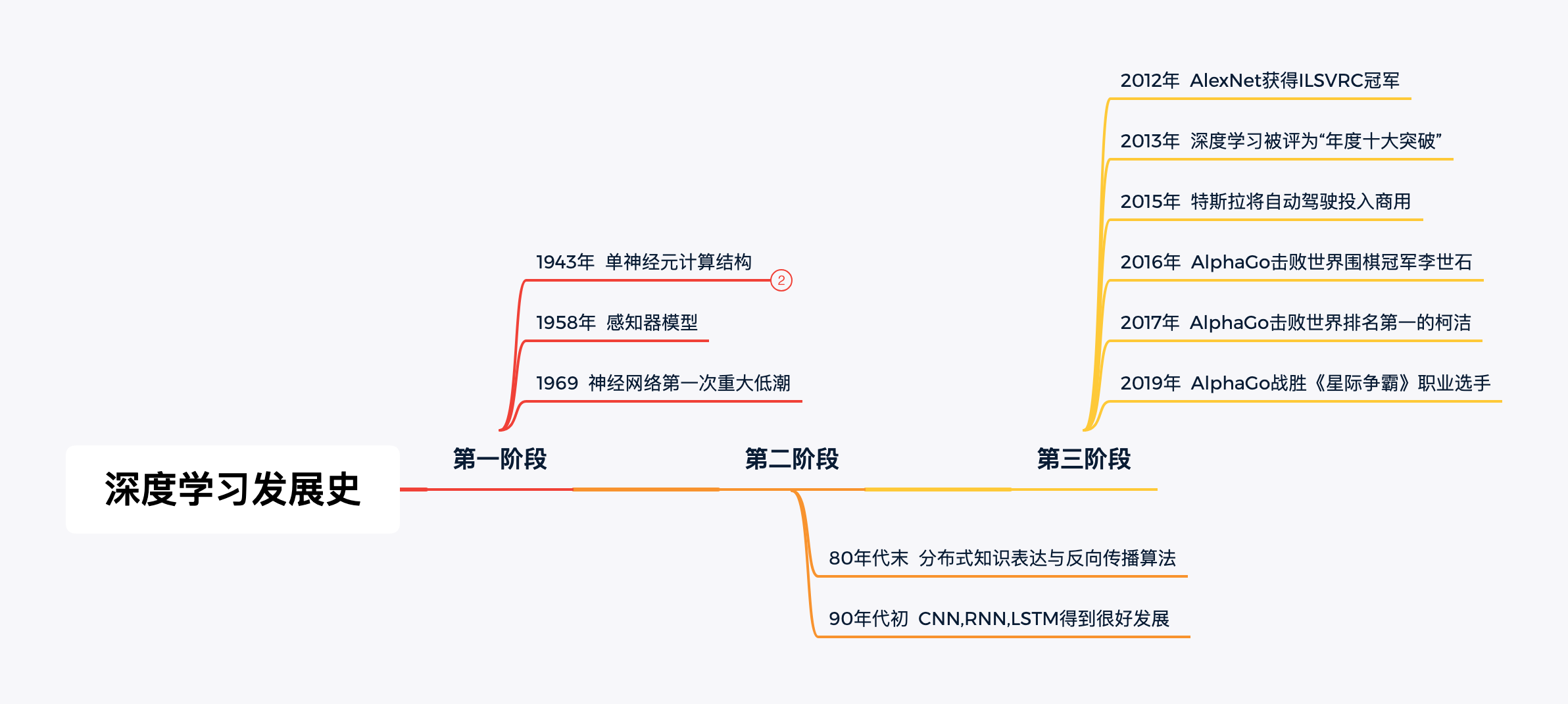
20世纪末,随着Hinton等人提出反向传播算法,深度学习迎来了又一波高潮,在各个领域都获得了巨大的成就,如最具代表性的领域「图像识别」。
基本概念
这一小节作者简单的介绍了神经网络的工作方式,下图展示了一个神经元的输出是输入数据加权和与偏置加和之后经过激活函数非线性 变换得到的结果。
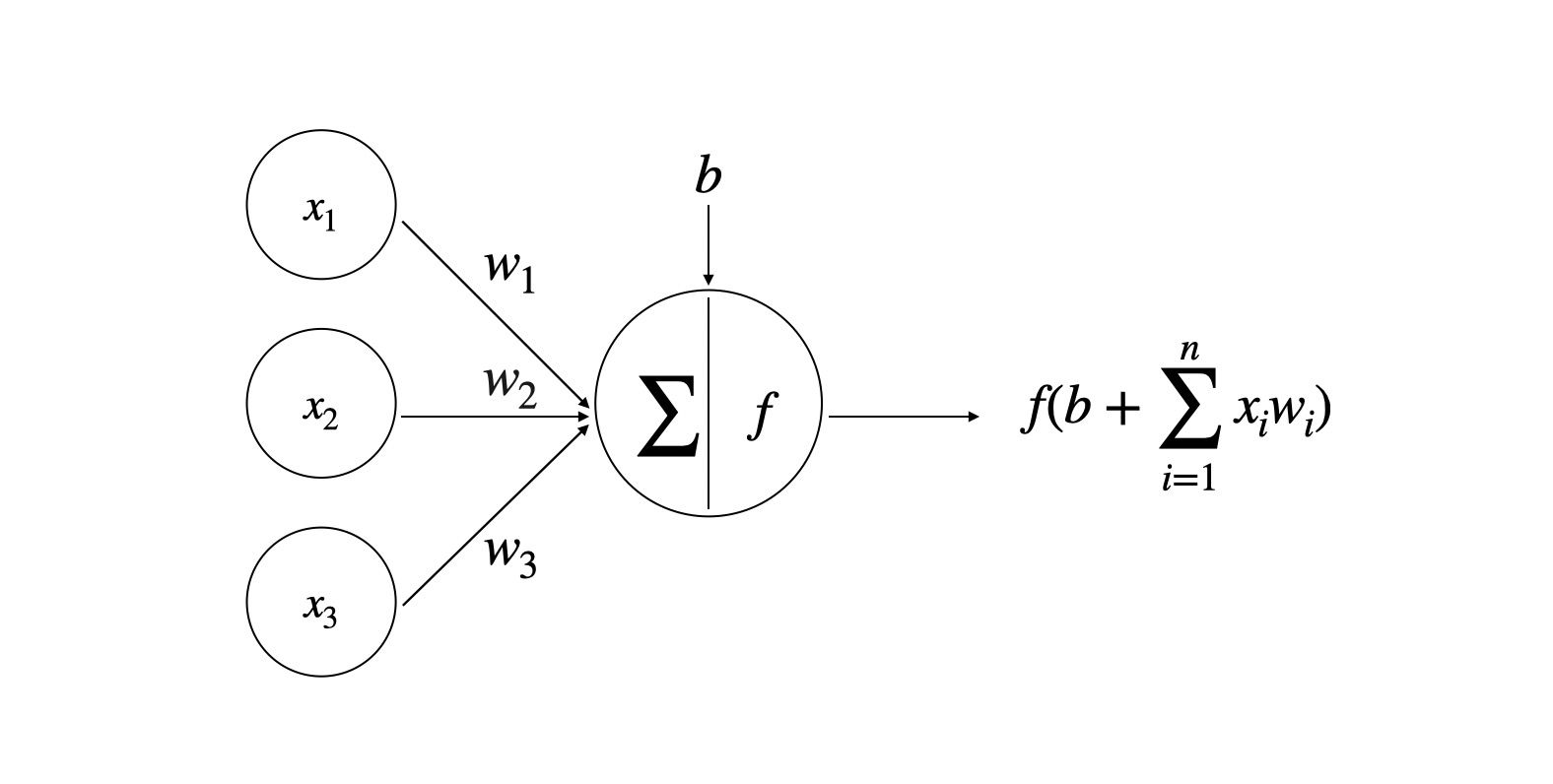
神经网络根据信号传递方向的不同分为前馈神经网络和反馈神经网络两种。前馈神经网络中,信号只允许向着输出的方向传播,前馈神经网络可以看做是有向无环图。反馈神经网络则允许信号重新接入到输出入层。
当前主流的 DNN 开发及运行框架包括:TensorFlow(Google) 、PyTorch(Facebook) 、Caffe(Berkeley 大学)。其它 DNN 框架如 Theano(Montreal 大学)、Keras(Keras-Team)、MXNet(Amazon)、CNTK(Microsoft)的 用户基础远比不上前三种。
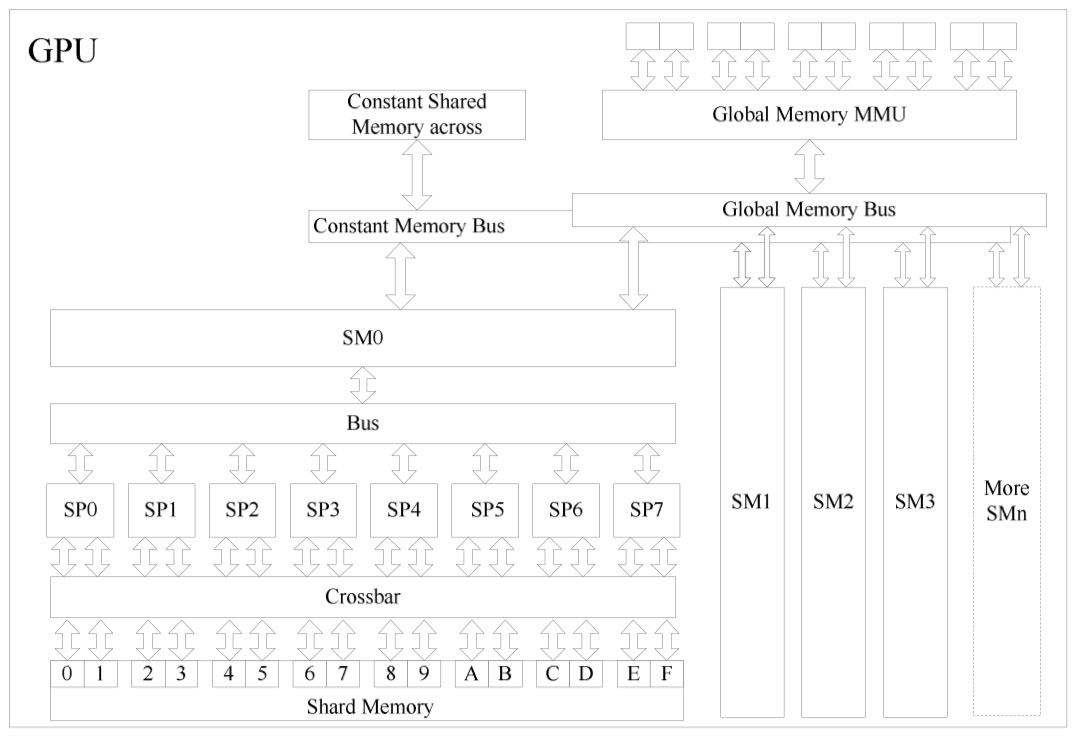
同时作者还介绍了PC平台GPU的基本结构、CUDA 程序的基本概念和基本运行规则,这部分是纯硬件理论知识,具体到线程、计算单元等单位。
DNN 任务在实时嵌入式系统中面临的挑战
嵌入式系统的共性特征是“实时性”,从应用的角度,实时性是指“不仅要保证运算的逻辑正确性,还必须保证运算在规定的时间内完成。DNN 任务(主要是推理过程)在实时嵌入式系统上的成功 部署与运行,既要在功能层面保证 DNN 推理结果的正确性和精确度,又要在非功能层面确保满足系统的实时性、资源和功耗的要求。
目前,DNN模型带来的关键问题主要有三个,分别是「传统DNN在实时嵌入式系统中具有局限性」、『通用深度学习框架设计并未考虑嵌入式平台实时性要求』和「DNN模型结构更新后不能保证系统的实时性」。
传统DNN在实时嵌入式系统中具有局限性
这是因为目前的DNN大多都不是在高性能的硬件平台上,如果把现有模型直接部署到资源受限的移动端,则难以满足「实时性」的要求。通过提升嵌入式的硬件性能是一种解决方案,但仍然具有局限性,另一种方法是在软件层面探索轻量化的网络设计和优化,即在模型的性能和占用资源、运行时间等方面进行权衡。
通用深度学习框架的设计并未考虑嵌入式平台的实时要求
当前流行的深度学习框架如「Tensorflow」、『PyTorch』等并未考虑顶层硬件和嵌入型平台的实时性要求,任务的资源分配时间没有上界,另一方面,即使是相同的神经网络不同深度学习框架上的运行时间也有较大差异,所以从深度学习框架的角度优化对于实时性任务也有较大提升空间。
DNN模型结构更新后不能保证系统的实时性
深度学习模型为了保证网络模型的预测精度和系统性能,往往需要对参数甚至网络结构进行调整,但当网络模型发生变化后,任务重新部署需要在资源受限的嵌入式设备时,需要重新满足一系列的约束条件,也就是说,计算平台需要有足够的计算资源来运行新的模型,并且不会违反任何时间限制。
硬件计算平台所面临的关键问题
GPU时间分析于调度管理技术
实时系统要求在系统实际执行之前,对时间行为进行分析,以确保在运行时系统的时间约束能够得到满足。 一般通过任务级时间行为分析,即最坏执行时间(Worst-Case Execution Time,WCET)分析,与系统级实时调度 与调度分析加以保证WCET分析的主要功能是分析程序的执行路径信息以及程序对硬件的访问行为,从而求得最坏执行时间.实时调度分析的目标是,在给定每个任务的 WCET 以及系统的实时调度算法的情况下,利用 数学手段分析系统中的所有任务是否能在截止期之前完成。在 GPU 目标硬件平台上部署实时 DNN 任务需要解决以下六个主要问题。
- 针对 GPU 的 WCET 分析和实时调度分析尚不成熟
- GPU 调度机制的细节信息不公开
- GPU 上执行混合关键任务会发生任务间干涉
- GPU 不支持对混合关键任务的抢占
- CPU+GPU SoC 平台上存在 CPU 和 GPU 之间协同的不确定性
- GPU 工作温度过高会自动触发 GPU 降频运行
DNN 任务性能分析与优化
这一章主要探讨了如何优化神经网络的性能和体积,我在上一篇文章『论文-轻量级神经网络架构综述』中已经有了详细的总结。
总结:这篇文章的侧重点在于「如何在嵌入式设备上部署满足实时性要求的模型」,针对这个问题,作者指出了现有深度学习框架模型的不足之处。我个人认为,将模型完全部署到移动端在某些特殊环境下是必要的(比如自动驾驶汽车,如果行驶到网络条件差的隧道或郊外就无法访问服务器,会造成严重的安全隐患)。但是我们的模型目前还必要部署到「移动端」,而是可以部署到计算资源比较充足的服务器端,再通过HTTP请求返回计算结果,这样就避免了这篇论文的核心问题,所以我觉得我们目前的工作和这篇论文的相关性还不是很明显。
More Details:Setting up your GitHub Pages site locally with Jekyll