Motivation
目前,传统的深度神经网络通过设计非常深的神经网络结构用于提取表达能力更强的深度特征,这对存储设备和计算资源的要求非常高,常用的便携式设备无法满足该需求,这严重限制了深度神经网络在便携式设备上的发展与应用。因此,为了提高便携式设备处理图像和视频数据的效率和能力,同时需要满足存储空间和功耗的限制,设计适用于便携式设备的轻量化深度神经网络架构是解决该问题的关键。
人工设计轻量级神经网络
为了能够在计算资源不算充足的设备上也能让神经网络获取较好的性能,涌现出很多人工设计的轻量级神经网络,如谷歌提出的MobileNet,ThunderNet,ShuffleNet,SqueezeNet等,这些人工设计的神经网络大多从三个方面对模型进行优化,分别是:「利用小卷积核替换大卷积核」,「限制中间特征的通道数量」,以及「分解卷及运算」。
利用小卷积核替换大卷积核
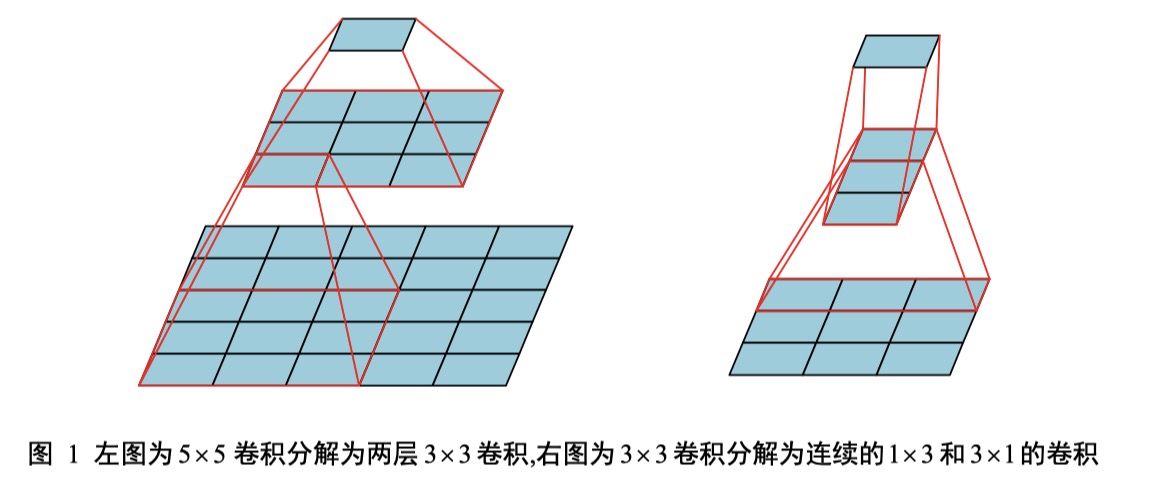
如图所示,相比于使用一个大的卷积核,多层小卷积核可以明显降低参数量,例如,一个5x5大小的卷积核参数量为25,假设我们使用2个3x3的卷积核,在效果上可以达到和5x5一致,但参数量却只有18个,相比减少了28%。不仅如此,使用多层小卷积核还可以明显降低FLOPs,首先让我们来了解一下FLOPs的定义:
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
由此可知,FLOPs是一个用来表示模型复杂度的物理量,它的数学表达式为: 其中,H和W分别代表输入的特征图片的高和宽,$C_{in}$代表输入通道数,$C_{out}$代表输出通道数,K代表卷积核的数量。 由此可以看出,将5x5的大卷积核替换为2个3x3的小卷积核后,FLOPs也相应减少,并且两层 3x3 卷积可以合并两层非线性层,比一层大卷积核更能增加非线性能力。
限制中间特征的通道数量
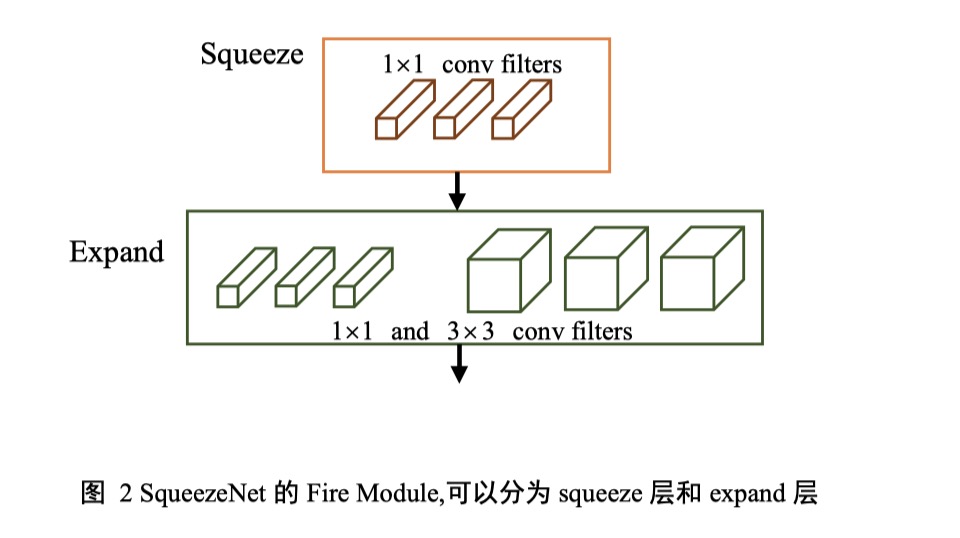
这个很好理解,根据公式 运算量受到输入通道数$C_{in}$ 和卷积核数量$K$的影响,一般来说卷积核数量代表提取的特征数量,减少会影响网络的准确率,如果可以减少$C_{in}$的值,那么计算量自然就会变小。这里作者提到了Iandola等人在『SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size』中提出了Fire model,在保证准确率的同时减少运算量。Fire module 包含两部分,压缩层(Squeeze)层和扩张层(Expand)层,通过减少 Squeeze 层的通道数量来减少整个模型需要的计算量。与 AlexNet相比,在保证了相同的性能的条件下,模型大小压缩了近 50 倍。这种方法论文里没有详细介绍,只给了一张图,所以也我没有完全理解,如果需要的话可以读一下上面的那篇论文好好学习一下。
分离卷积运算
深度可分离卷积(Depthwise Separable Convolution)可分为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个操作。深度卷积(Depthwise Convolution)对于每个输入通 道采用不同的卷积核即一个通道对应一个卷积核,卷积操作是按照通道进行分解的;逐点卷积(Pointwise Convolution)是卷积核大小为 1x1 的标准卷积,作用在输入的所有通道上,将来自不同通道的特征进行融合。
这部分作者详细介绍了分离卷积运算的具体过程,之前对这部分知识没有深入了解,只知道一些轻量级的网络,如MobileNet中,会有深度可分离卷积操作,这次正好借着这个机会研究了一番。
常规卷积操作
对于一张5×5像素、三通道(shape为5×5×3),经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4,最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
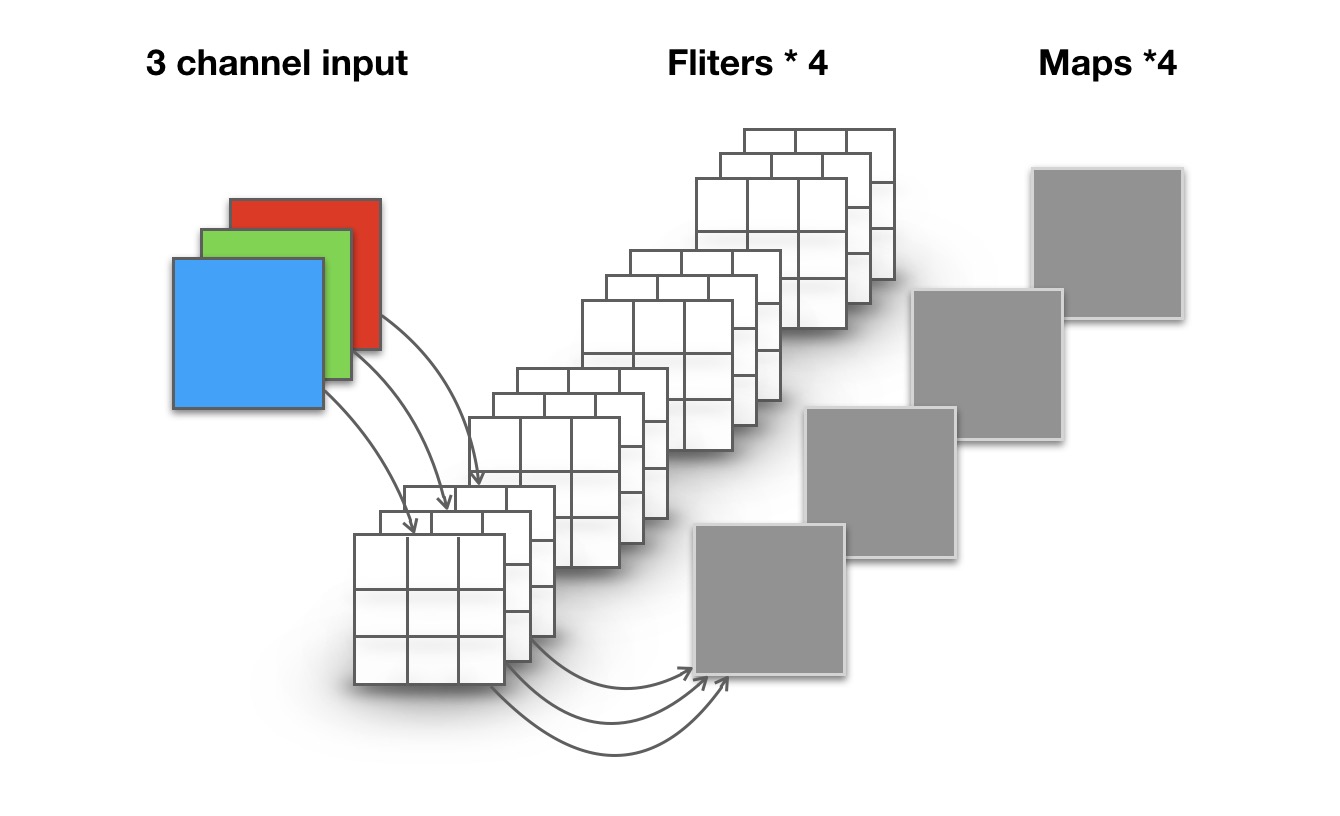
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
深度可分离卷积
逐通道卷积
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
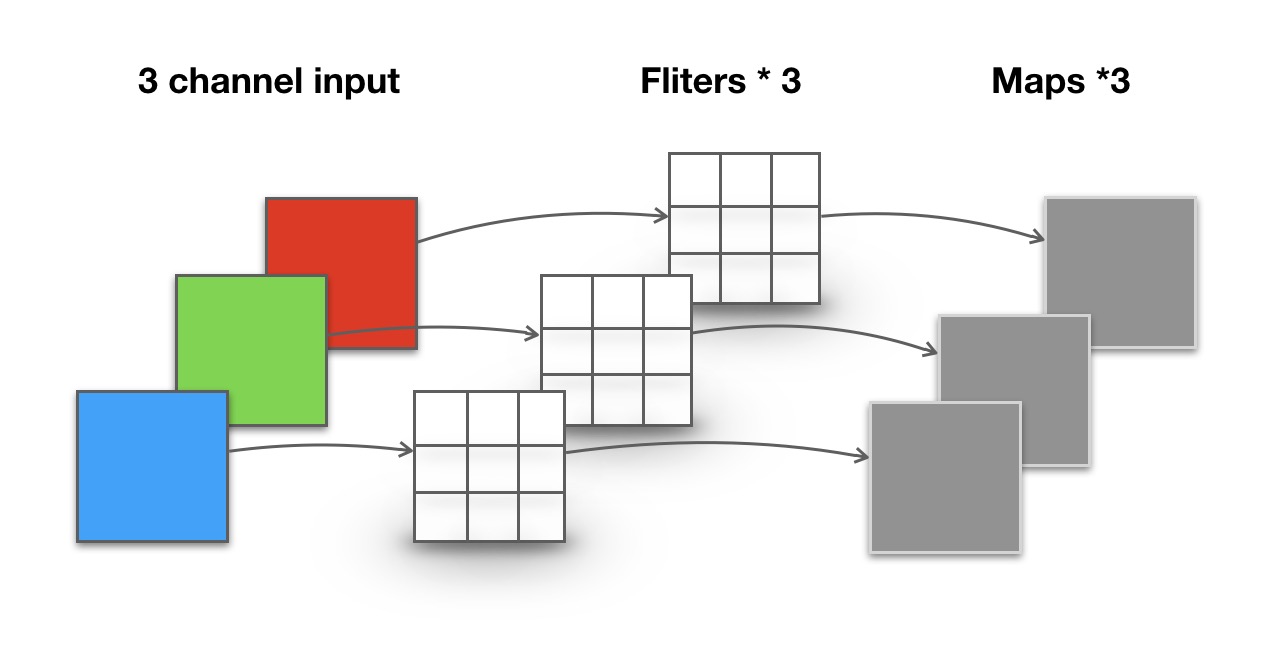
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
逐点卷积
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
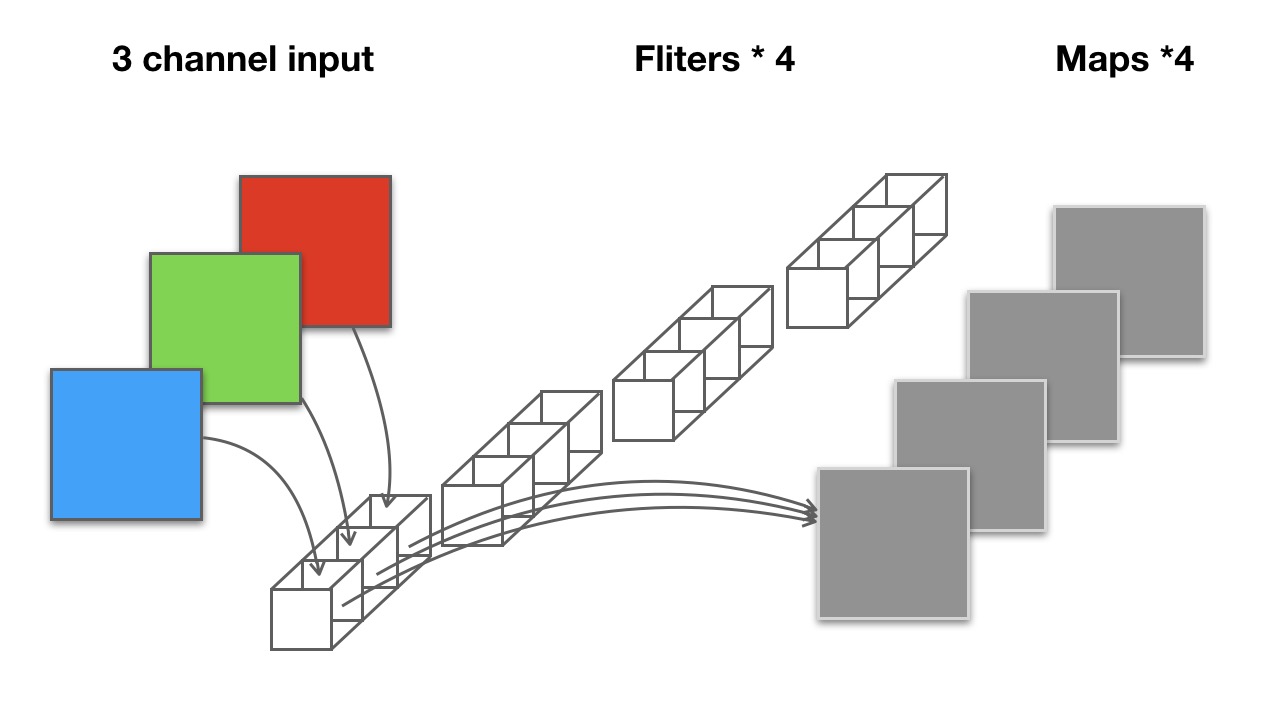
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
Separable Convolution的参数由两部分相加得到:
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
卷积神经网络的压缩方法
设计轻量级网络结构的另一种方法是模型压缩,根据神经网络在不同方面的冗余,分别使用网络的分支裁剪,减少网络权重占用的比特数,对卷积核 进行低秩分解,知识蒸馏等方法,对已有的网络模型进行压缩,降低对空间和计算能力的需求,实现在便携设备上的实时运行。
剪枝
剪枝是指对网络结构中的权重进行删减从而达到压缩网络的目的。由于神经网络中很多神经元的参数在实际应用中的作用都是微乎其微的,所以可以通过剪枝的方法来将这些不重要的神经元剔除,剪枝不但可以减少模型的存储空间,还可以降低模型对计算能力的要求,同时增加运行速度。在之前写的论文中,我和庞总也使用过剪枝的方法,将模型的参数量从900,000减少到300,000。
权重量化
权重量化很好理解,它的指导思想是将用于存储权重的16位浮点数缩短为8位或更低,在略微损失精度的基础上,可以得到非常高的压缩比,但是这种方法需要专门的运算策略来实现。比较成功的方法还有二值神经网络,即网络中的权重只有1和-1两种,这样就有了32~64倍的压缩率,使网络的运行效率大幅提升。
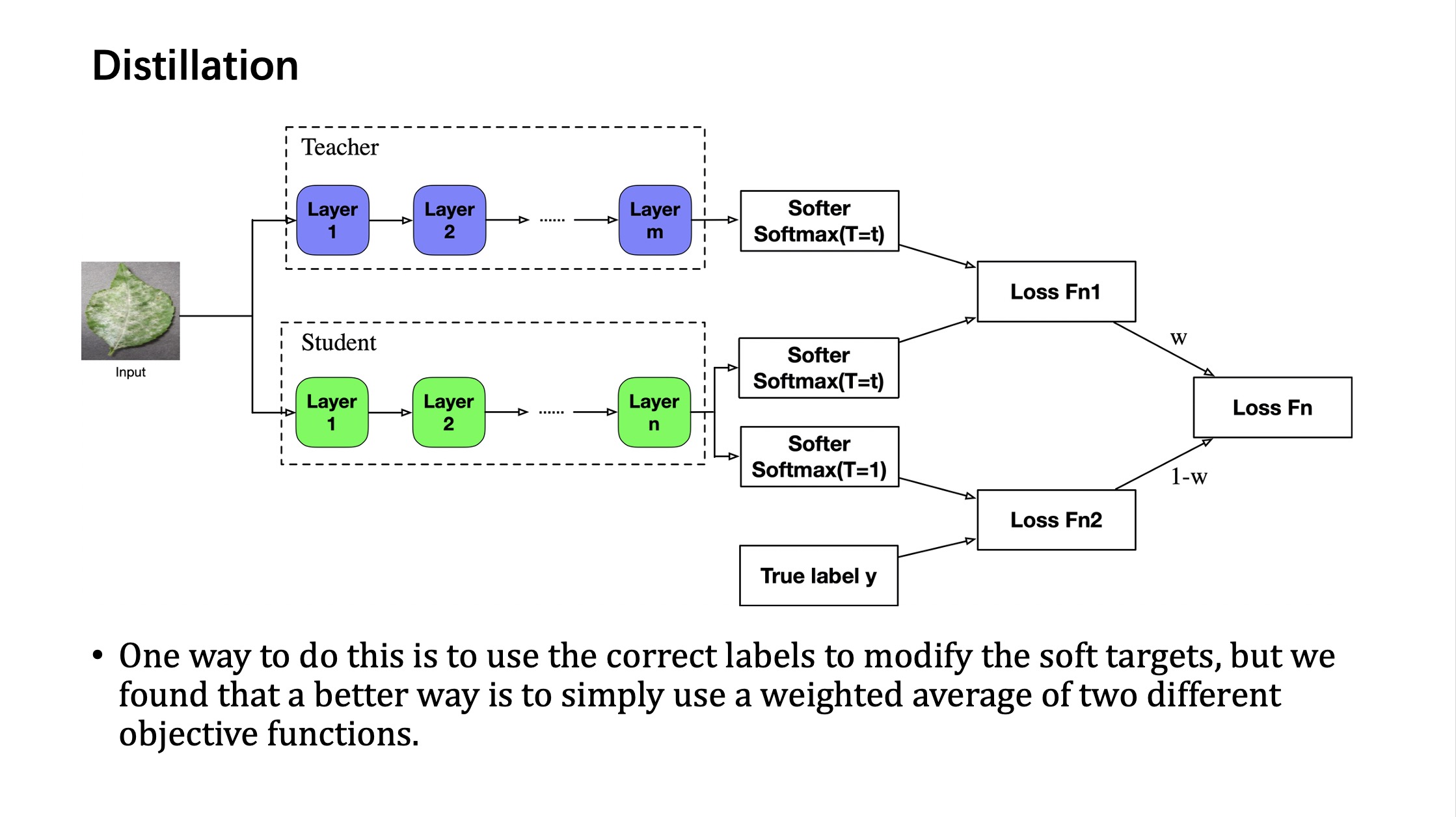
知识蒸馏
Hinton 首先提出了知识蒸馏的概念,让小网络在学习分类目标的同时,也尽量拟合大网络对不同类别的软分类结果。由于这篇文章之前已经学习过,就不再赘述,附一张知识蒸馏的图示。
基于神经网络架构搜索的自动化轻量级神经网络设计
这部分我看的比较粗,一方面是因为,自动化的轻量级网络结构设计目前只针对特定任务有更好的表现,难以结合到我们的研究中,另一方面是因为大多数「自动产生的网络结构」还不如MobileNet、ResNet等通用网络结构能在轻量的同时保持较高准确率。所以只对这种方法做一个简单的介绍,不过多讨论。
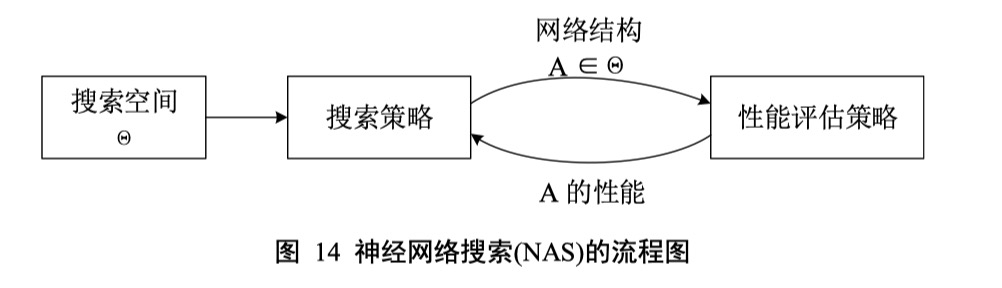
由于人工设计网络结构对设计者的要求很高,不仅要求设计者具有深厚的理论知识,并且还要经过大量的实验验证,需要耗费很多人力物力,因此提出了「基于神经网络架构搜索」,即在给定的搜索空间内自动设计神经网络的结构。神经网络架构搜索分为三个步骤:「搜索空间」、「搜索策略」和「性能评估策略」。
搜索空间
搜索空间的作用是限定网络的基本结构单元,以便用于网络结构的组合。搜索空间根据结构的不同分为两种,一种是直接搜索整个网络架构的全局搜索空间,另一种是重复某些特定结构的局部搜索空间(如卷积层和池化层之间的重复)。
搜索策略
当完成构建搜索空间后,搜索策略决定了如何在搜索空间内搜索针对特定任务的基本架构单元,并确定 神经网络内部的连接方式。一方面需要快速找到性能良好的神经网络架构,另一方面需要避免过早的收敛到次优的神经网络架构。
性能评估策略
性能评估策略用于评估网络结构的好坏,通常需要对特定网络结构重新进行训练并测试,因此这个过程非常耗时,近年来围绕这个问题许多学者做过研究,致力于寻找高效、便捷的模型评估策略。
总结
作者介绍了目前存在的三种构建轻量级神经网络的主流方法,分别是人工设计轻量级神经网络、神经网络模型压缩算法和基于神经网络架构搜索的自动化神经网络架构设计。其中前两种已经应用于我们的实验中并取得了不错的表现。在看这篇文章的过程中,自己之前有很多模糊的概念,都随着作者的思路慢慢捋顺了,有还是不懂的地方,比如「深度卷积」和『逐点卷积』这两个概念,也通过查资料重新回炉了一遍。遗憾的地方是,由于这是一篇综述性质的文章,所以作者只介绍了目前的工作进展,并未介绍每种方法的具体工作原理,所以下一步我打算从作者介绍的三种主流方法中找几篇具体的论文来看,不仅拓宽广度,更要挖掘深度。
More Details:Setting up your GitHub Pages site locally with Jekyll